Note: Below are some responses to frequently asked questions that have been posed to us by students, reviewers, and interested scholars. Of course, our responses reflect our views on the state of the field at this moment in time; they will be updated as new data become available. Please don't hesitate to email us if we can clarify anything further! - Paul Eastwick and Eli Finkel
PREDICTIVE VALIDITY OF IDEAL PARTNER PREFERENCES
What are “ideal partner preferences,” and how should they be related to romantic evaluations of partners?
Ideal partner preferences (also called “mate preferences” and “ideal standards”) are the qualities that people rate highly when thinking about their ideal romantic partner. Typically, researchers operationalize ideals with respect to traits, such as attractiveness or warmth or extraversion. I might say that I want a partner who is especially extraverted, whereas you might say you want a partner who is not especially extraverted.
When we test the predictive validity of ideals, we are asking the question: Does the extent to which a partner matches my ideals predict how positively I evaluate him/her?
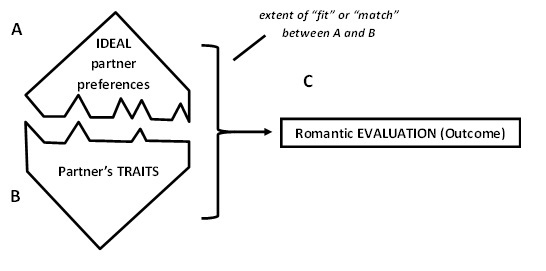
That is, does the extent of matching between (A) the participant’s ideals (e.g., desiring extraversion in a partner) and (B) the partner’s traits (e.g., the partner’s level of extraversion) predict (C) the participant’s evaluation of the partner (e.g., how much the participant loves the partner)? Answering this question typically requires measures of all three constructs, which we refer to as the ideal, the trait, and the evaluation, respectively.
How do you assess the extent to which someone’s ideals match the traits of a partner?
There are two ways to compute “match.” The first is the ideal × trait interaction, which captures the extent to which the fit between one ideal trait and the partner’s level of that trait predicts romantic evaluation, over and above the main effect of ideal and the main effect of trait alone. We have called this approach the level metric. The second approach is that, for each dyad in your sample, you can compute a correlation between a participant’s ideals and a partner’s traits across multiple traits; this approach captures the relative fit between a set of ideals and corresponding traits. We call this the pattern metric. These two metrics are independent (Cronbach, 1955, called them elevation and accuracy). You can use either metric to predict the romantic evaluation outcome.
Do the level metric and pattern metric matching indexes predict romantic evaluations?
For the level metric, the answer is consistently “no”. That is, ideal × trait interactions do not reliably predict romantic evaluations. This means that, if I say I really care about extraversion in a partner and you say you do not, extraversion tends to predict evaluations of romantic partners about the same for both of us.
For the pattern metric, the answer is “yes, if people are evaluating a current romantic partner.” That is, to the extent that a current partner matches my pattern of ideals (regardless of level) across a variety of traits, I report more positive romantic evaluations about him/her. If people instead evaluate partners they aren’t currently dating, then the answer is again “no.” (The clearest demonstration of these effects is in Study 3 here as well as Study 4 here.)
Importantly, new evidence suggests that the pattern metric has some statistical shortcomings (see Statistical Critique #2 below), so take these findings with a grain of salt.
Is there a published resource with more detail?
Yes. Check out this manuscript .
SEX DIFFERENCES AND IDEAL PARTNER PREFERENCES
Why would you even include speed-dating in the meta-analysis? Isn’t it a particularly artificial setting?
If you have ever seen a speed-date (a real one, not this one), you will probably have seen two people discussing some pretty ordinary details about their lives (e.g., where they are from, what they do for a living and/or study). They meander through these topics while trying to find something in common. Having interactions like these 12 times in a row might not be your cup of tea, but it’s a relatively ordinary getting-acquainted interaction.
Is there a published resource with more detail?
Yes. Please check out “Section 1: Sex differences in Ideal Partner Preferences” in this manuscript.
CONCEPTUAL CRITIQUES
STATISTICAL CRITIQUES
Statistical critique #1: People’s ideals correlate with their actual partner’s traits. That is, if I want an intelligent partner, my partner is more likely to be intelligent. Doesn’t this demonstrate that people are fulfilling their ideals by selecting partners who match their ideals?
Maybe. Or maybe it means that people’s ideals change to match the traits of their current partners (they do). Or it means that people’s ideals change to match the traits that members of one’s preferred sex generally possess (e.g., men report greater ideals for physical attractiveness because women are more attractive than men). Or it means that people tend to live near partners who match their ideals, and these are the partners that people happen to meet and start dating. Or it means that people move to areas with partners who match their ideals. All these explanations are interesting and plausible.
To put it another way: Findings that examine only the correlation between ideals and traits (e.g., Conroy-Beam & Buss, 2016; Campbell, Chin, & Stanton, 2016) omit evaluations (i.e., the crucial third variable—the DV—in the model depicted above). These perspectives assume that the partner was evaluated positively and therefore selected in favor of alternative partners. But the evaluations are not measured, and the alternative, unselected partners are not observed. Thus, in our view, there are myriad alternative explanations for these effects, and they cannot address our core question of “Do people positively evaluate romantic partners to the extent that those partners match their ideals?” These correlations could be interesting for a number of reasons, but it’s hard to know (without measuring additional variables) what causes them to emerge.
Statistical critique #2: Just use the pattern metric, then! It’s better than the level metric because it captures more traits.
We used to believe this…but now we don’t. The reason why we have changed our minds on the viability of the pattern metric is because of this paper by Wood and Furr (2015). These authors point out that similarity metrics (of which the pattern metric is one example) have embedded within them a large chunk of variance due to normative positivity. This “Normative Desirability Confound” means that the pattern metric might correlate with DVs like desire or satisfaction for a really boring reason: We like people who have positive traits.
There are ways of correcting the pattern metric for this concern. In our view, the whole prior literature using the pattern metric (including our own papers!) are inconclusive until the Wood and Furr (2015) critique can be addressed. More research is needed.
Statistical critique #3: Just ask people “to what extent does your partner match your ideals for attractiveness?” These items predict evaluations strongly.
These items (which we call “direct-estimation” items) dodge the pattern vs. level metric issue by simply asking participants to make the matching judgment themselves. We think participants answer these items by simply reporting the extent to which the partner possesses the trait. Indeed, a direct-estimation item like “to what extent does your partner match your ideals for attractiveness” correlates with the judgment “to what extent does your partner possess the trait attractiveness” at about r = .90 (Rodriguez, Hadden, & Knee, 2015). Correlations that high are a pretty strong indicator that you assessed the same construct twice.
So direct-estimation items probably predict romantic evaluations because perceptions of positive traits predict romantic evaluations. It probably doesn’t have anything to do with ideals.
Statistical critique #4: Don’t speed-daters exhibit a truncated range of traits? I don’t think unattractive people or people with poor earning potential go speed-dating.
This critique almost certainly does not apply to attractiveness. Consider these data from one of our speed-dating studies. Here, the speed-dating participants rated each other on physically attractive and sexy/hot on 1 (not at all) to 9 (extremely) scales. Here is a histogram of the average of these two items (N on the y axis; each speed-dater rated ~12 targets):

We might be missing some exceptionally attractive people, but otherwise, this looks pretty uniform.
In an interesting twist, consider what happens if you ask coders to rate photographs of these same people:

Now, it looks as if speed-daters are mostly unattractive people. But the reality is, this is what happens when you ask coders to rate photographs: they tend to be really harsh, and about 80-90% of the judgments fall below the midpoint of the scale. So this isn’t something about speed-dating…it’s something about how people judge photographs.
As for earning potential (an average of good career prospects and ambitious/driven), we’re open to this critique in the context of our collegiate speed-dating events:
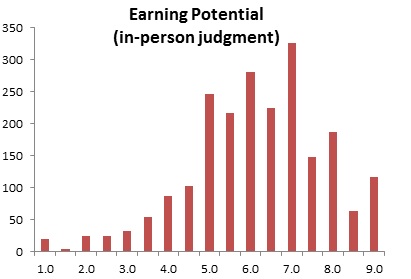
Here, about 75% of people are above the midpoint of the scale.
One reason we’re not too concerned about this critique (broadly speaking) is that earning potential was not truncated in the studies in our meta-analysis. In fact, many of those studies were representative samples that incorporated people’s actual income as a predictor! So although this critique applies fairly to our speed-dating studies, the meta-analytic results reassure us that our results generalize to representative samples.